|
|||||||||||

!!! Dieses Dokument stammt aus dem ETH Web-Archiv und wird nicht mehr gepflegt !!!
!!! This document is stored in the ETH Web archive and is no longer maintained !!!
!!! This document is stored in the ETH Web archive and is no longer maintained !!!
CP2K: High Performance Computing
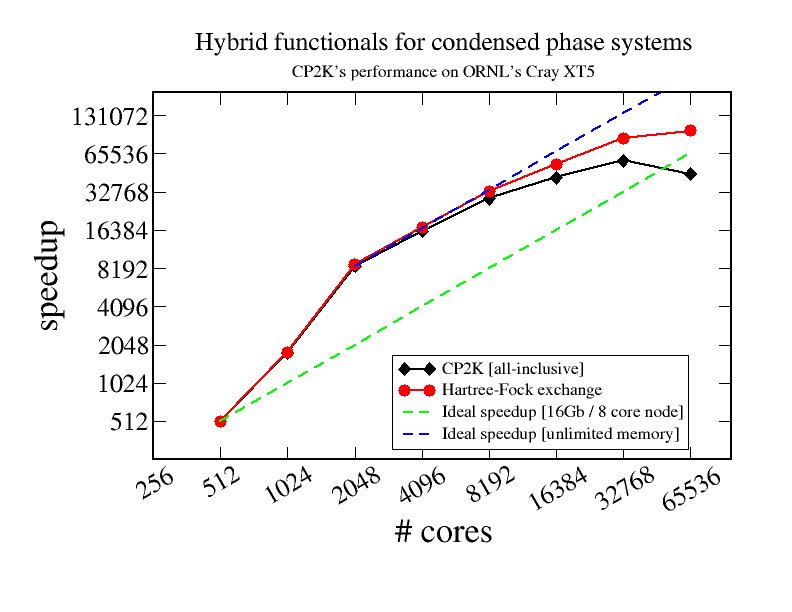
High performance computing (HPC) is a crucial ingredient to extend the reach of simulation and consequently it is an important aspect of my research. Particularly illustrative (Fig. 4) is our massively parallel implementation of Hartree-Fock exchange which has been demonstrated to exhibit strong scaling to more than 32000 cores of a Cray XT5.[34,41,42] The implementation employs a hybrid MPI/OMP approach, which facilitates load balancing, reduces communication, and allows for a more efficient symmetry-respecting algorithm. Storage of intermediate integrals speeds up the calculation by a large factor, but, even after our novel in RAM variable precision compression scheme[34], can exceed 10Tb in cases where the underlying sparse matrix exceeds dimensions 109 x 109.[41,42,47] Most important for reaching this scalability is the load balancing algorithm, which features several levels of resolution, to retain a manageable size of the load balancing problem, yet yields an almost perfect load balance even for inhomogeneous systems.
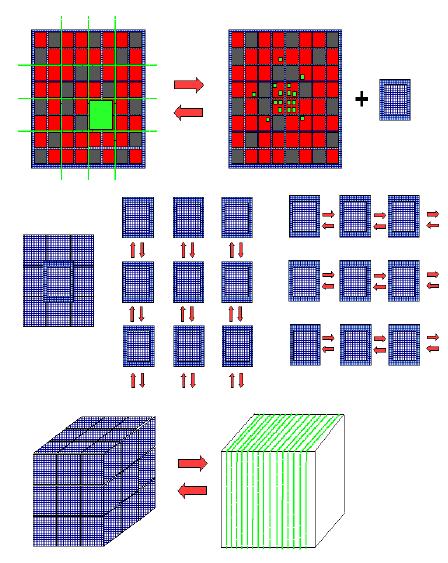
The computationally very demanding Hartree-Fock exchange calculations can now be parallelized very well. The more common simulations based on semi-local DFT benefit from our efforts to improve strong scaling of the basic Gaussian and Plane Waves (GPW) scheme. The major improvement has been a fully distributed version of the core algorithm which transforms a distributed sparse matrix via an intermediate 3D decomposed domain with halos to a 1D or 2D decomposed Fourier grid (See Fig. 5). With this implementation, it has become possible to run large systems on architectures that have only a small amount of memory per core, but many cores. Simulations now scale well up to about 1-4 atoms per core, with a limit of about 1024 cores. Ultimately, linear algebra, based on scalapack, usually limits the performance. A forthcoming change from dense to sparse linear algebra is likely to improve performance and the code's weak scaling behavior.
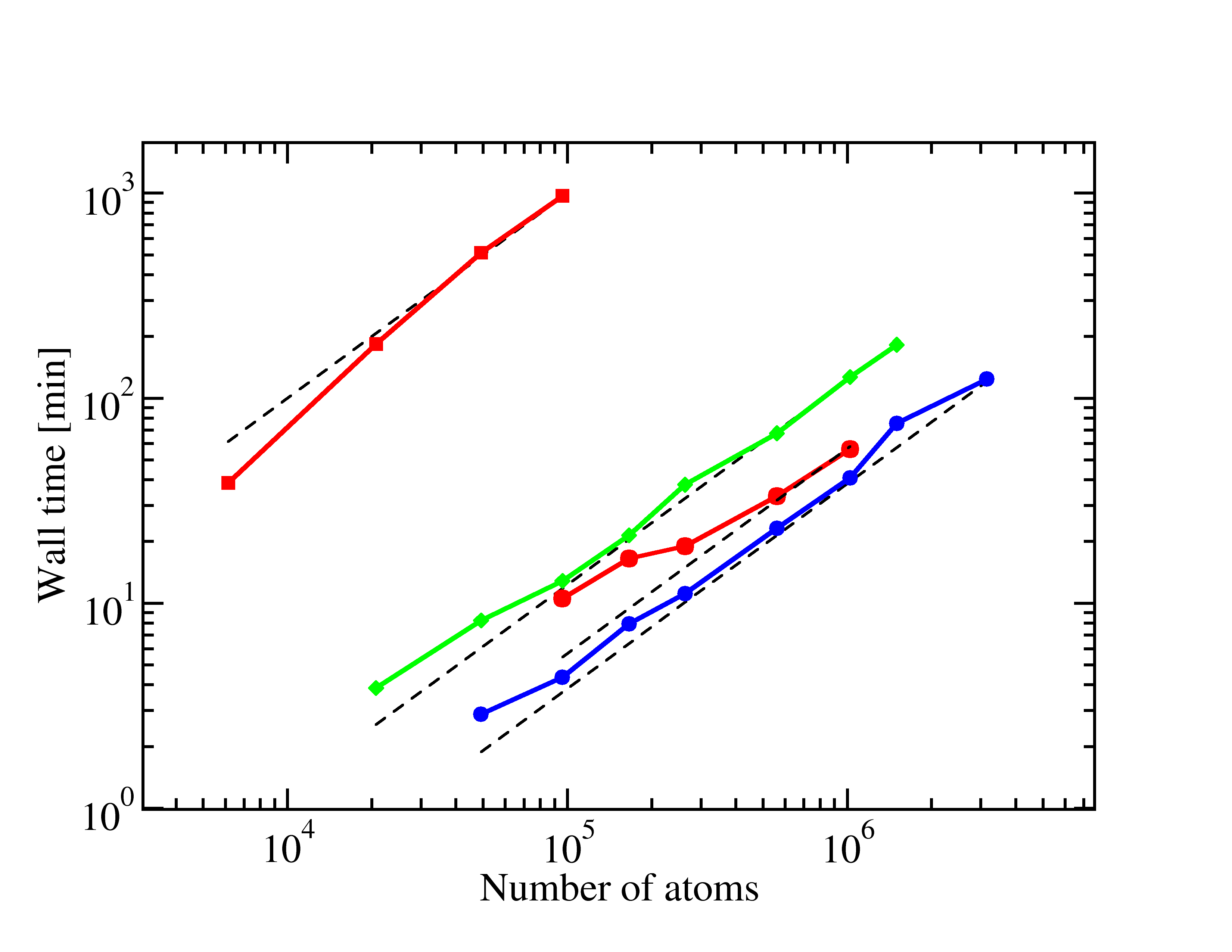
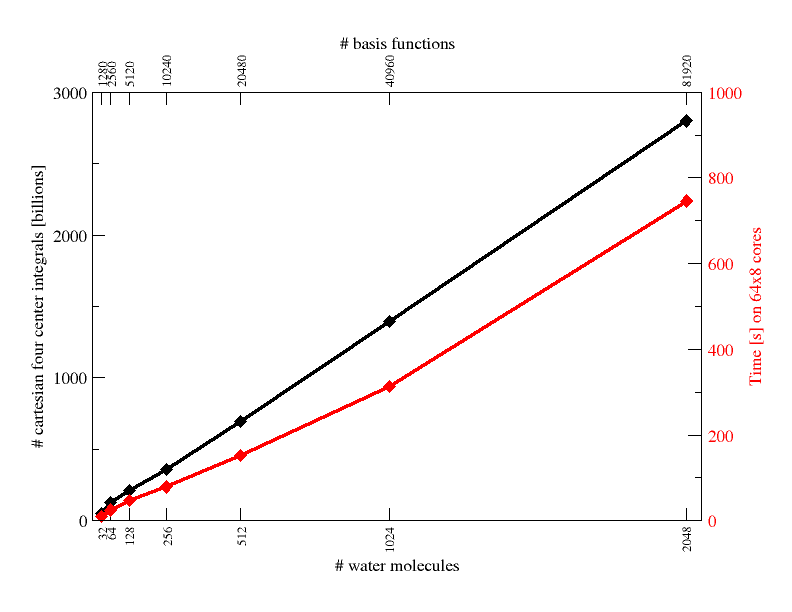
As systems become larger, only approaches that have a computational cost that grows proportionally with system size remain truly useful. Recently, we have been able to make to eliminate all non-linear scaling algorithms from the GGA DFT part of CP2K, allowing us for the first time to perform self-consistent DFT calculations for millions of atoms in the condensed phase (See Fig 6). Similarly, our Hartree-Fock exchange code has been shown to be in the linear scaling regime for dense systems up to a few thousand atoms (See Fig 7)
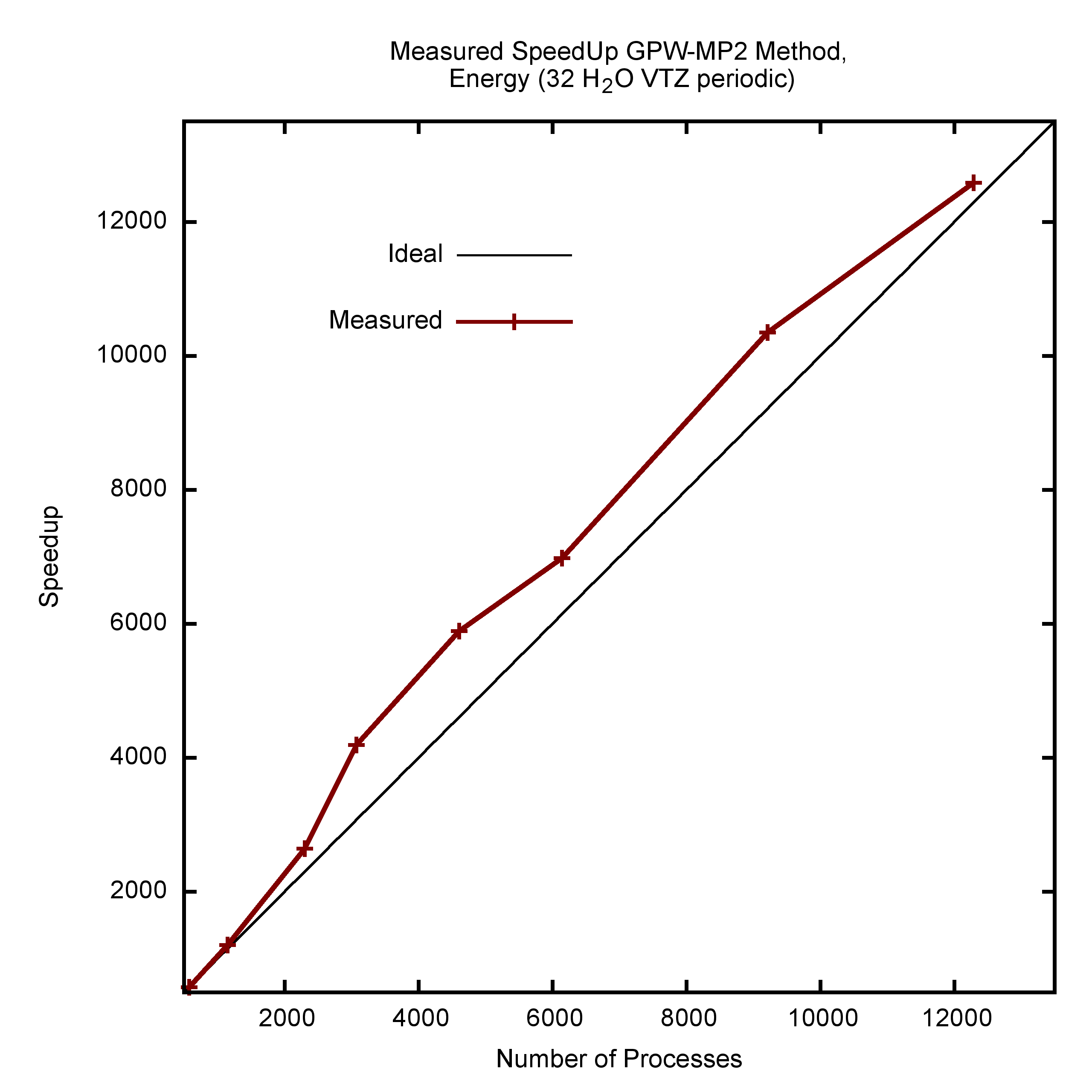
| Recent work focuses on the development of MP2 methods to add correlation beyond DFT to CP2K. Formally MP2 scales as O(N5) and most implementations require a lot of communication, limiting parallel scalability. With a new algorithm based on the GPW scheme, we observe O(N3) scaling up to a few hundred atoms, excellent efficiency and superb parallel scalability (See Fig 8). |
Wichtiger Hinweis:
Diese Website wird in älteren Versionen von Netscape ohne
graphische Elemente dargestellt. Die Funktionalität der
Website ist aber trotzdem gewährleistet. Wenn Sie diese
Website regelmässig benutzen, empfehlen wir Ihnen, auf
Ihrem Computer einen aktuellen Browser zu installieren. Weitere
Informationen finden Sie auf
folgender
Seite.
Important Note:
The content in this site is accessible to any browser or
Internet device, however, some graphics will display correctly
only in the newer versions of Netscape. To get the most out of
our site we suggest you upgrade to a newer browser.
More
information

!!! Dieses Dokument stammt aus dem ETH Web-Archiv und wird nicht mehr gepflegt !!!
!!! This document is stored in the ETH Web archive and is no longer maintained !!!
!!! This document is stored in the ETH Web archive and is no longer maintained !!!